Künstliche Intelligenz und maschinelles Lernen in der Cybersicherheit
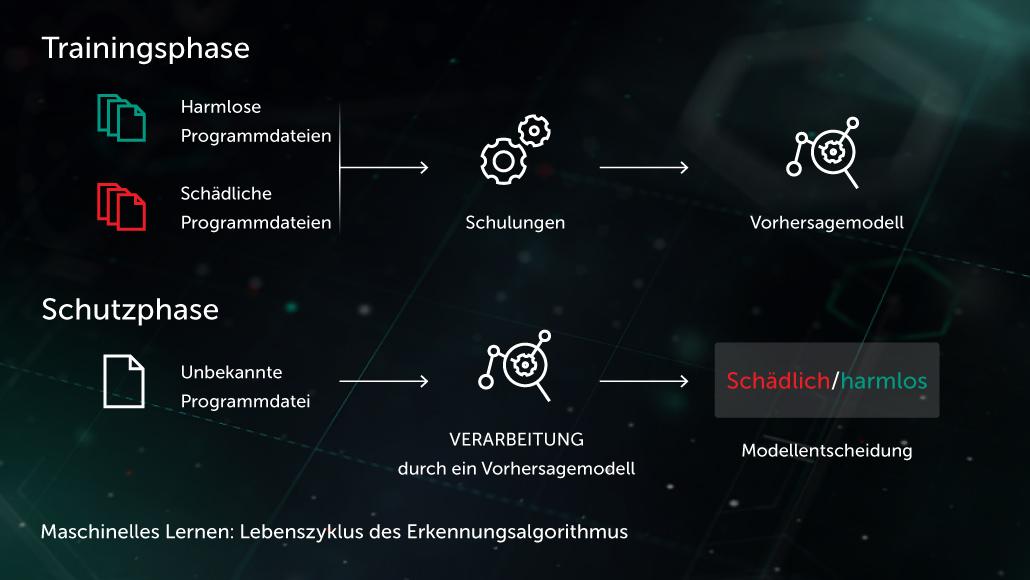
Arthur Samuel, ein Pionier auf dem Gebiet der künstlichen Intelligenz, beschrieb KI als einen Satz von Methoden und Technologien, die „Computern die Fähigkeit verleihen zu lernen, ohne explizit programmiert zu werden“. Im speziellen Fall des beaufsichtigten Lernens für Anti-Malware könnte die Aufgabe wie folgt formuliert werden: Ausgehend von einem Satz von Objektmerkmalen \( X \) und entsprechenden Objektbezeichnungen \( Y \) als Input wird ein Modell erstellt, das die korrekten Bezeichnungen \( Y‘ \) für bisher ungesehene Testobjekte \( X‘ \) erzeugt. \( X \) könnten dabei Merkmale sein, die den Dateiinhalt oder das Dateiverhalten darstellen (Dateistatistik, Liste der verwendeten API-Funktionen usw.), während die Bezeichnungen\( Y \) einfach „Malware“ oder „gutartig“ sein könnten (in komplexeren Fällen könnte man eine detailliertere Klassifizierung wie Virus, Trojaner-Downloader, Adware usw. verwenden). Beim nicht gesteuerten Lernen sind wir eher daran interessiert, verborgene Strukturen innerhalb der Daten aufzudecken, wie z. B. Gruppen von ähnlichen Objekten oder Merkmale mit starkem Bezug zueinander.
Der mehrschichtige Next Generation-Schutz von Kaspersky nutzt Methoden der KI wie maschinelles Lernen umfassend in allen Phasen der Erkennung – von skalierbaren Clustering-Methoden zur Vorverarbeitung eingehender Dateiströme bis hin zu robusten und kompakten Modellen für tiefe neuronale Netzwerke zur Verhaltenserkennung, die direkt auf den Rechnern der Benutzer arbeiten. Diese Technologien sind so konzipiert, dass real existierenden Programmen für die IT-Sicherheit gleich mehrere wichtige Anforderungen an Cybersicherheitsprogramme in der realen Welt erfüllen, nämlich weniger False Positives, Interpretierbarkeit der Modelle und Robustheit gegenüber potenziellen Gegnern.
Die wichtigsten auf ML basierenden Technologien, die in den Endpoint-Produkten von Kaspersky verwendet werden, sollen im Folgenden vorgestellt werden:
Entscheidungsbäume
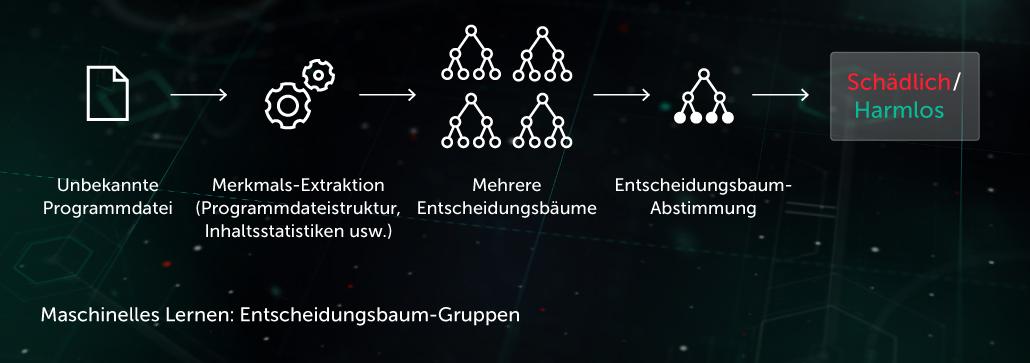
Bei diesem Ansatz besteht das Vorhersagemodell aus einer Reihe von Entscheidungsbäumen (z. B. Random Forest oder Gradient Boosted). Jeder weiter verzweigte Node eines Baumes enthält eine Frage zu den Merkmalen einer Datei, während der Node ohne untergeordneten Zweig die endgültige Entscheidung des Baumes über das Objekt enthält. Während der Testphase durchläuft das Modell den Entscheidungsbaum, indem es die Fragen in den Nodes mit den entsprechenden Merkmalen des betrachteten Objekts beantwortet. In der Endphase werden die Entscheidungen mehrerer Bäume anhand von spezifischen Algorithmen gemittelt, um eine endgültige Entscheidung über das Objekt zu treffen.
Am Endpoint unterstützt das Modell die vorausschauende Schutzschicht, die vor der Ausführung wirkt. Eines unserer Programme mit dieser Technologie ist Cloud ML for Android, das zur Erkennung mobiler Bedrohungen eingesetzt wird.
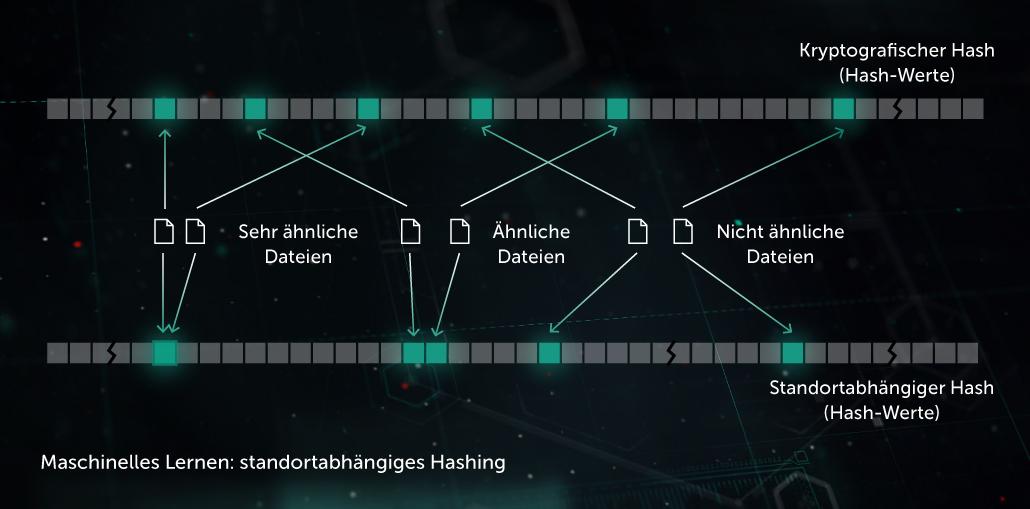
Ähnlichkeits-Hash (Locality-Sensitive Hashing)
In der Vergangenheit reagierten Hash-Werte, die zur Erstellung von Malware-Profilen eingesetzt wurden, auf jede kleine Änderung in einer Datei. Diesen Umstand nutzten Malware-Entwickler über Verschleierungstechniken wie z. B. serverseitigen Polymorphismus aus, bei dem die Malware schon durch kleinste Änderungen der Erkennung entging. Ähnlichkeits-Hashing (oder Locality-Sensitive Hashing) ist eine KI-Methode zur Erkennung ähnlicher schädlicher Dateien. Zu diesem Zweck extrahiert das System Dateimerkmale und ermittelt mithilfe der orthogonalen Projektion, welche Merkmale die wichtigsten sind. Anschließend werden die Wertvektoren ähnlicher Merkmale mithilfe der ML-basierten Kompression in ähnliche oder identische Muster umgewandelt. Mit dieser Methode lässt sich eine gute Verallgemeinerung erzielen und die Zahl der Datensätze aus der Erkennung erheblich verringern, da ein Datensatz jetzt eine ganze Familie von polymorpher Malware erkennen kann.
Am Endpoint unterstützt das Modell die vorausschauende Schutzschicht, die vor der Ausführung wirkt. Verwendung findet es in unserem Similarity Hash Detection System.
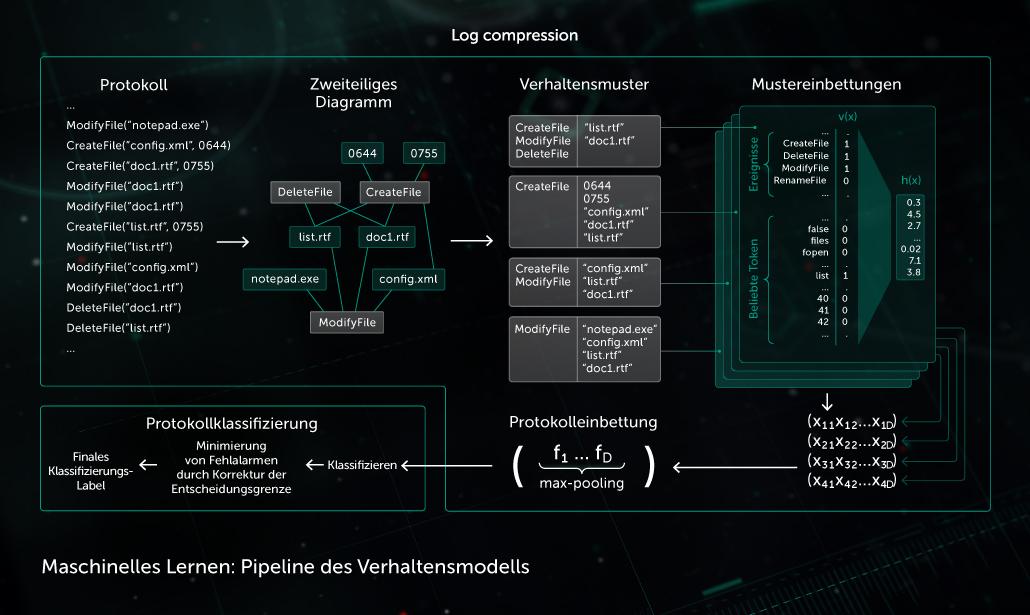
Verhaltensmodell
Eine Überwachungskomponente stellt ein Verhaltensprotokoll zur Verfügung – eine Abfolge von Systemereignissen, die während der Prozessausführung auftreten, zusammen mit entsprechenden Argumenten. Um schädliche Aktivitäten in den untersuchten Protokolldaten zu erkennen, fasst unser Modell die eingegangene Ereignisfolge in einen Satz von binären Vektoren zusammen und trainiert das tiefe neuronale Netzwerk, damit es saubere von schädlichen Protokolle unterscheiden kann.
Die vom Verhaltensmodell vorgenommene Objektklassifizierung wird in Kaspersky-Produkten Endpoint-seitig sowohl von statischen als auch von dynamischen Erkennungsmodulen angewendet.
Eine ebenso wichtige Rolle spielt KI beim Aufbau einer geeigneten Infrastruktur, um Malware im Labor verarbeiten zu können. Kaspersky nutzt ML Infrastruktur-seitig zu folgenden Zwecken:
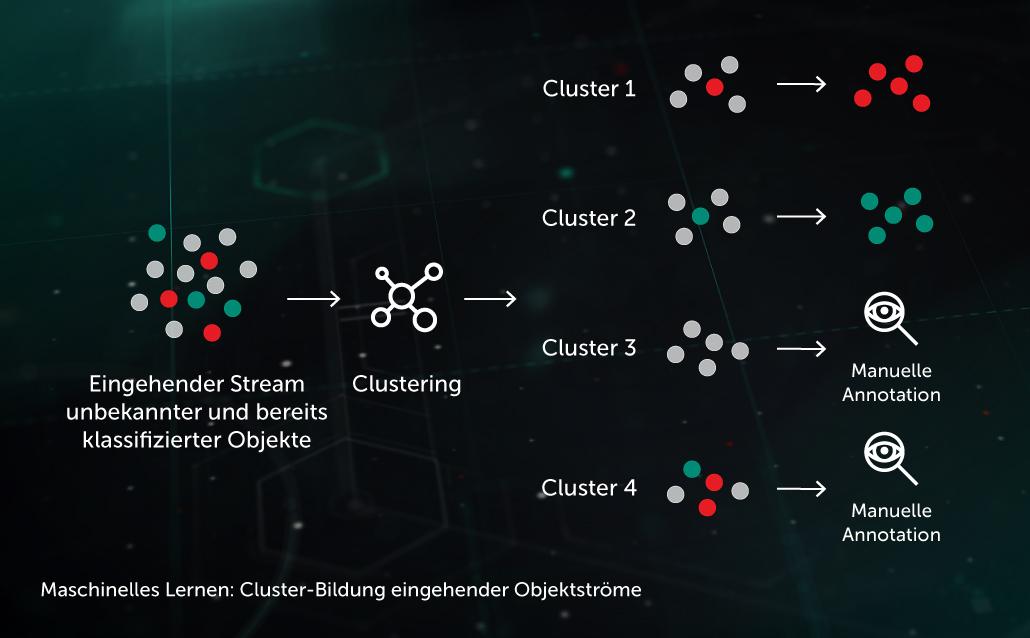
Clustering eingehender Streams
Algorithmen für das Clustering mithilfe lernfähiger Systeme bieten uns die Möglichkeit, die große Zahl an unbekannten Dateien, die in unsere Infrastruktur gelangen, effizient in einer übersichtlicheren Zahl von Clustern zusammenzufassen. Einige dieser Cluster, die bereits ein klassifiziertes Objekt enthalten, können dann auch sofort automatisch verarbeitet werden.
Umfassende Vorhersagemodelle
Einige der leistungsfähigsten Klassifizierungsmodelle (wie ein riesiger Random Forest von Entscheidungsbäumen) erfordern signifikante Ressourcen (Prozessorzeit, Speicher) sowie teure Extrahierungskomponenten für Dateimerkmale (wenn beispielsweise detaillierte Verhaltensprotokolle in einer Sandbox verarbeitet werden müssen). Daher ist es oft effektiver, die Modelle in einem Labor auszuführen und die daraus gewonnenen Erkenntnisse als Trainingsmaterial in ein weniger schwergewichtiges Klassifizierungsmodell einfließen zu lassen.
Sicherheit bei der Nutzung von ML innerhalb der KI
Sobald ML-Algorithmen außerhalb der engen Grenzen des Labors der realen Welt ausgesetzt sind, bieten sie eine gute Angriffsfläche für verschiedenste Arten von Angriffen, die darauf abzielen, KI-Systeme dazu zu zwingen, bewusste Fehler zu machen. So kann ein Angreifer die Trainingsdaten verunreinigen oder den Code des Modells durch Reverse Engineering manipulieren. Außerdem können Hacker ML-Modelle mit Hilfe speziell entwickelter „feindlicher KI“-Systeme per „Brute Force“ aushebeln – die automatisch viele Angriffsmuster generieren und gegen die Schutzlösung oder das extrahierte ML-Modell einsetzen, bis eine Schwachstelle des Modells entdeckt wird. Die Auswirkungen solcher Angriffe auf Malware-Schutzsysteme auf Basis von KI können verheerend sein: Ein falsch identifizierter Trojaner bedeutet Millionen von infizierten Geräten und den Verlust vieler Millionen Dollar.
Aus diesem Grund müssen beim Einsatz von KI in Sicherheitssystemen einige wichtige Überlegungen angestellt werden:
- Der Sicherheitsanbieter sollte die wesentlichen Anforderungen an die Leistungsfähigkeit der KI-Komponenten in der realen, potentiell feindlichen Welt kennen und sorgfältig danach handeln – Anforderungen, wie zum Beispiel die Robustheit gegenüber potentiellen Gegnern. ML/KI-spezifische Sicherheitsprüfungen und „Red Teaming“ sollten Schlüsselkomponenten, wenn bei der Entwicklung von Sicherheitssystemen KI herangezogen wird.
- Bei der Bewertung der Sicherheit einer Lösung, die KI-Komponenten verwendet, sollte man nachfragen, inwieweit die Lösung von Daten und Architekturen Dritter abhängt, da viele Angriffe auf dem Input Dritter basieren (wir sprechen von Threat Intelligence Feeds, öffentlichen Datensätzen, vortrainierten und ausgelagerten KI-Modellen).
- ML/KI-Methoden sind kein Allheilmittel, sondern müssen in einen mehrstufigen Sicherheitsansatzes integriert werden, bei dem Schutztechnologien und menschliches Fachwissen einander ergänzen und sich gegenseitig schützen.
Kaspersky hat zwar in seinen Cybersicherheitslösungen bereits viel Erfahrung mit der effizienten Nutzung von KI-Komponenten wie ML und Deep Learning, allerdings handelt es sich bei diesen Technologien nicht um echte KI oder Artificial General Intelligence (AGI). Bis Maschinen wirklich selbstständig arbeiten und die meisten Aufgaben völlig autonom erledigen können, kann noch eine ganze Weile dauern. Bis dahin kommt keine KI-Komponente in der Cybersicherheit ohne die Anleitung und das Fachwissen von menschlichen Fachleuten aus, die diese Systeme entwickeln und verfeinern und ihre Fähigkeiten mit der Zeit erweitern.
Eine detaillierte Übersicht über weit verbreitete Angriffe auf ML/KI-Algorithmen und Methoden zum Schutz vor diesen Bedrohungen finden Sie in unserem Whitepaper „KI im Kreuzfeuer: Absicherung künstlicher Intelligenz in Sicherheitssystemen“.
Verwandte Produkte
Kaspersky Anti Targeted Attack Platform

Kaspersky Endpoint Security for Business
Kaspersky Small Office Security
 Whitepaper
Whitepaper
WhitepaperMachine Learning for Malware Detection
Whitepaper
WhitepaperMachine learning and Human Expertise
Whitepaper
WhitepaperAI under Attack: How to Secure Machine Learning in Security System